
AI智能体问答知识库

AI智能体问答知识库
Pupper软件测试相关知识库
一、软件测试概述
1.1 定义与目标
- 定义:软件测试是通过人工或自动化手段验证系统是否满足需求,并评估软件质量的过程。
- 核心目标:
- 发现缺陷(Defect/Bug)
- 验证功能符合需求规格
- 评估系统性能、安全性和可靠性
- 降低产品风险,提升用户满意度
1.2 测试基本原则
- 测试显示缺陷的存在(无法证明无缺陷)
- 穷尽测试不可行(需通过风险评估确定优先级)
- 早期测试(需求阶段介入,遵循Shift-Left原则)
- 缺陷集群性(少数模块包含多数缺陷)
- 杀虫剂悖论(需定期更新测试用例)
- 测试依赖上下文(不同场景需不同策略)
1.3 测试生命周期(STLC)
- 需求分析 → 2. 测试计划 → 3. 用例设计 → 4. 环境搭建 → 5. 测试执行 → 6. 缺陷管理 → 7. 报告与复盘
二、软件测试分类
2.1 按测试层级分类
| 测试类型 | 测试对象 | 典型工具 | 验证目标 |
|---|---|---|---|
| 单元测试 | 代码函数/类 | JUnit, pytest, Mockito | 代码逻辑正确性 |
| 集成测试 | 模块/服务间接口 | Postman, RestAssured | 接口通信与数据交互 |
| 系统测试 | 完整系统 | Selenium, Appium | 端到端业务流程 |
| 验收测试 | 用户视角功能 | Cucumber, Robot Framework | 商业需求符合性 |
2.2 按测试目的分类
- 功能测试:验证需求文档中定义的功能(如登录、支付流程)
- 非功能测试:
- 性能测试:负载测试(Load Testing)、压力测试(Stress Testing)
- 安全测试:渗透测试(OWASP Top 10漏洞扫描)
- 兼容性测试:跨浏览器/设备/OS验证
- 可用性测试:用户体验评估(导航路径、界面友好度)
2.3 按测试策略分类
- 黑盒测试:基于需求文档,不关注内部实现(等价类划分、边界值分析)
- 白盒测试:基于代码结构(路径覆盖、条件覆盖)
- 灰盒测试:结合黑盒与白盒(如API测试)
三、测试用例设计方法
3.1 经典方法
- 等价类划分(有效/无效输入)
- 边界值分析(如最小值-1、最大值+1)
- 决策表(多条件组合场景)
- 状态迁移(如订单状态机测试)
- 因果图(复杂逻辑的图形化分析)
3.2 基于场景的方法
- 用户故事测试(Given-When-Then格式)
- 端到端(E2E)流程测试(如电商下单全链路)
- 异常流测试(网络中断、数据超时等)
四、缺陷管理
4.1 缺陷生命周期
- 新建(New) → 2. 分配(Assigned) → 3. 修复中(In Progress) → 4. 已修复(Fixed) → 5. 验证(Verified) → 6. 关闭(Closed)
注:可能包含“拒绝(Rejected)”“重新打开(Reopened)”等状态。
4.2 缺陷报告要素
- 标题:简洁描述问题(如“支付页面在iOS 15.4下无法提交订单”)
- 优先级(Priority):修复紧急程度(P0-P3)
- 严重程度(Severity):对系统影响(Blocker, Critical, Major等)
- 复现步骤:明确的操作路径(Step-by-Step)
- 环境信息:OS版本、浏览器、设备型号等
- 附件:日志、截图、视频等
4.3 缺陷管理工具
- JIRA:支持自定义工作流,与CI/CD集成
- Bugzilla:开源轻量级工具
- Redmine:支持多项目管理
- 禅道:国产一体化工具(需求-用例-缺陷联动)
五、自动化测试
5.1 自动化适用场景
- 高重复性用例(如每日构建后的冒烟测试)
- 复杂计算验证(如金融系统的利率计算)
- 多环境兼容性测试(跨浏览器/设备组合)
- 性能压测(模拟大规模并发请求)
5.2 主流自动化框架
| 类型 | 框架/工具 | 适用场景 |
|---|---|---|
| Web UI | Selenium, Cypress | 浏览器端功能测试 |
| 移动端 | Appium, Espresso | Android/iOS应用测试 |
| API | Postman, RestAssured | 接口自动化与Mock服务 |
| 性能 | JMeter, Gatling | 负载测试与TPS测量 |
| 低代码 | Katalon, TestComplete | 快速实现无代码脚本 |
5.3 自动化测试设计原则
- 稳定性优先:避免用例因环境波动频繁失败
- 模块化与复用:采用Page Object Model(POM)模式
- 数据驱动:分离测试数据与脚本(Excel/JSON/YAML)
- 失败重试机制:应对网络抖动等临时问题
六、性能测试深度解析
6.1 性能指标
- 响应时间:90%用户请求在X秒内完成
- 吞吐量(Throughput):系统每秒处理请求数(TPS/RPS)
- 资源利用率:CPU、内存、磁盘I/O、网络带宽
- 错误率:失败请求占比(应低于0.1%)
6.2 性能测试类型
| 类型 | 目标 | 场景示例 |
|---|---|---|
| 基准测试 | 建立性能基线 | 单用户请求响应时间 |
| 负载测试 | 验证系统在预期压力下的表现 | 模拟1000用户同时登录 |
| 压力测试 | 探索系统极限与故障恢复能力 | 逐步增加负载至系统崩溃 |
| 稳定性测试 | 检测长时间运行下的内存泄漏/资源累积 | 持续压测8小时 |
6.3 性能优化策略
- 数据库优化:索引调整、慢查询分析
- 缓存机制:Redis缓存热点数据
- 代码级优化:减少循环嵌套、避免内存泄漏
- 架构扩展:水平扩展(增加服务器)、读写分离
七、测试环境与DevOps集成
7.1 测试环境类型
- 本地环境:开发者本地调试
- 集成环境:持续集成(Jenkins/GitLab CI)触发自动化测试
- 预发布环境:与生产环境1:1配置,用于最终验证
- 容器化环境:Docker/Kubernetes实现快速环境重建
7.2 CI/CD中的测试策略
- 代码提交阶段:单元测试 + 静态代码分析(SonarQube)
- 构建阶段:接口自动化测试 + 基础性能测试
- 发布前:全量回归测试 + 安全扫描(OWASP ZAP)
- 生产环境:A/B测试 + 监控告警(Prometheus/Grafana)
八、测试人员核心技能
8.1 技术能力
- 编程语言:Python/Java/JavaScript
- SQL与NoSQL:数据校验与测试数据构造
- 网络协议:HTTP/HTTPS、TCP/IP抓包分析(Wireshark)
- Linux命令:日志分析(grep)、进程管理(ps/kill)
8.2 软技能
- 需求分析能力:从模糊描述中提取可测试点
- 沟通协作:推动开发复现缺陷,明确责任边界
- 风险意识:识别关键路径与优先级排序
九、安全测试专项
9.1 安全测试核心目标
- 机密性:防止未授权访问敏感数据(如用户密码、支付信息)。
- 完整性:确保数据在传输/存储中未被篡改。
- 可用性:抵御DoS/DDoS攻击,保障服务持续可用。
- 审计与合规:满足GDPR、PCI-DSS等法规要求。
9.2 常见安全漏洞与攻击类型
9.2.1 OWASP Top 10 2021(关键漏洞)
| 漏洞类型 | 原理简述 | 检测与利用场景 |
|---|---|---|
| 注入攻击 | 通过未过滤的用户输入执行恶意代码(如SQL、OS命令) | SQL注入:' OR 1=1 -- 绕过登录;工具:SQLMap |
| 失效的身份认证 | 弱密码、Session固定、JWT令牌泄露 | 暴力破解(Hydra)、JWT密钥猜测(jwt_tool) |
| 敏感数据泄露 | 明文传输密码、未加密存储信用卡号 | 抓包工具(Wireshark)、日志文件分析 |
| XML外部实体(XXE) | 解析恶意XML文件导致文件读取/SSRF | 上传包含<!ENTITY xxe SYSTEM "file:///etc/passwd">的XML文件 |
| 访问控制缺失 | 垂直越权(普通用户访问管理员接口)、水平越权(访问他人数据) | 修改URL参数(如/user/123 → /user/456) |
| 安全配置错误 | 默认配置未修改(如开放调试端口)、CORS策略过宽 | 扫描开放端口(Nmap)、检查HTTP头(如Access-Control-Allow-Origin: *) |
| XSS(跨站脚本) | 恶意脚本注入到页面中执行(存储型、反射型、DOM型) | 输入<script>alert(1)</script>,工具:Burp Suite Scanner |
| 不安全的反序列化 | 反序列化未验证数据导致远程代码执行(RCE) | Java/C#反序列化漏洞(ysoserial工具生成Payload) |
| 使用已知漏洞组件 | 第三方库(如Log4j 2.x的CVE-2021-44228) | 依赖扫描工具(OWASP Dependency-Check、Snyk) |
| 日志与监控不足 | 未记录关键事件,无法追踪攻击行为 | 模拟攻击后检查日志完整性(如登录失败记录是否缺失) |
9.2.2 其他高危漏洞
- CSRF(跨站请求伪造):诱导用户点击链接执行非预期操作(如修改密码)。
- SSRF(服务端请求伪造):利用服务端发起内网请求(如访问
http://localhost/admin)。 - 文件上传漏洞:绕过文件类型检查上传Webshell(如
.php.jpg双重扩展名)。 - 业务逻辑漏洞:重复提交订单、价格篡改(前端校验绕过)。
9.3 安全测试工具链
| 工具类型 | 代表工具 | 用途 |
|---|---|---|
| 漏洞扫描 | Nessus, OpenVAS | 自动化扫描系统/Web应用漏洞 |
| 渗透测试 | Burp Suite, Metasploit | 手动探索漏洞(Burp用于Web渗透,Metasploit用于漏洞利用) |
| 网络侦查 | Nmap, Wireshark | 端口扫描、流量抓包分析 |
| 密码破解 | John the Ripper, Hashcat | 暴力破解哈希或弱密码 |
| 代码审计 | SonarQube, Checkmarx | 静态代码分析(SAST)检测潜在漏洞 |
| 动态分析 | OWASP ZAP, sqlmap | 自动化SQL注入/XSS检测 |
| 容器安全 | Clair, Trivy | 扫描Docker镜像中的漏洞 |
9.4 安全测试方法论
9.4.1 渗透测试流程(PTES标准)
- 前期交互:明确测试范围(黑盒/白盒)、签署授权协议。
- 信息收集:
- WHOIS查询、子域名枚举(Sublist3r)
- 目录遍历(Dirbuster)、API端点发现(Postman)
- 威胁建模:识别高危模块(如支付、用户中心)。
- 漏洞利用:尝试攻击路径(如通过XSS获取Cookie → 越权访问)。
- 后渗透利用:横向移动(内网渗透)、数据窃取。
- 报告与修复:提供漏洞详情、复现步骤、修复建议(如CWE标准)。
9.4.2 测试类型选择
- 黑盒测试:模拟外部攻击者,无系统内部知识。
- 白盒测试:基于源码/设计文档的全面审计。
- 灰盒测试:部分信息(如API文档)辅助测试。
9.5 安全防御最佳实践
9.5.1 开发阶段
- 输入验证:白名单过滤(如正则表达式限制邮箱格式)。
- 参数化查询:避免SQL拼接(使用PreparedStatement)。
- 安全编码:避免
eval()、system()等危险函数。
9.5.2 部署与运维
- 防火墙规则:限制非必要端口访问(如关闭3306 MySQL端口)。
- WAF(Web应用防火墙):拦截常见攻击(ModSecurity规则集)。
- 定期更新:修补系统/组件漏洞(如Apache Struts版本升级)。
9.5.3 监控与响应
- 日志集中化:ELK(Elasticsearch, Logstash, Kibana)实时分析。
- 入侵检测系统(IDS):Snort规则匹配异常流量。
- 应急响应计划:制定漏洞修复SOP(如48小时内修复高危漏洞)。
9.6 案例场景
案例1:JWT令牌安全性
- 漏洞:使用弱密钥(如
secret123)签发JWT,攻击者通过暴力破解伪造管理员令牌。 - 修复:采用强密钥(HS256算法)、增加过期时间、校验令牌签名。
案例2:OAuth配置错误
- 漏洞:未校验
redirect_uri,攻击者构造恶意回调地址窃取授权码。 - 修复:严格校验回调域名、启用PKCE(Proof Key for Code Exchange)。
十、AI在测试中的应用
10.1 AI驱动测试的核心价值
- 效率提升:自动化生成测试用例,减少人工设计成本
- 精准预测:基于历史数据识别高风险模块,优化测试优先级
- 复杂场景覆盖:处理非结构化数据(如图像、自然语言)的验证
- 自适应维护:动态调整测试脚本应对UI/API变更
10.2 关键技术原理
| 技术方向 | 应用场景 | 典型算法/模型 |
|---|---|---|
| 机器学习(ML) | 缺陷预测、测试优化 | 决策树、随机森林(分类高风险模块) |
| 深度学习(DL) | 图像识别、自然语言处理 | CNN(视觉回归测试)、RNN/Transformer(日志分析) |
| 强化学习(RL) | 自动化测试路径探索 | Q-Learning(动态生成最优操作序列) |
| 大语言模型(LLM) | 测试用例生成、需求解析 | GPT-4、Codex(将自然语言需求转为自动化脚本) |
10.3 典型应用场景
10.3.1 测试用例生成
- 基于需求文档:
LLM解析用户故事,输出Gherkin格式用例(示例):1
2
3
4
5
6# 输入:用户登录需验证手机号格式
Scenario: 验证无效手机号登录
Given 用户打开登录页面
When 输入手机号"123456"
And 点击"获取验证码"按钮
Then 显示错误提示"手机号格式不正确" - 基于代码分析:
工具(如Diffblue)通过AST分析代码分支,生成单元测试覆盖边界条件。
10.3.2 自动化脚本维护
- 自愈测试(Self-Healing):
当UI元素XPath变更时,AI通过图像识别(如Applitools)自动定位新元素并更新定位器。 - 视觉回归测试:
对比基线截图与测试截图,DL模型(如SikuliX)识别细微差异(如像素偏移、颜色偏差)。
10.3.3 缺陷预测与根因分析
- 缺陷密度预测:
基于代码复杂度、历史缺陷数据训练模型,输出模块风险等级(高危/中危/低危)。1
2
3
4# 示例:使用随机森林预测缺陷概率
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train_features, y_train_defect_labels) - 日志聚类分析:
NLP模型(如BERT)对海量日志分类,快速定位异常模式(如OutOfMemoryError高频出现)。
10.3.4 性能测试优化
- 智能负载生成:
RL模型模拟用户行为分布,动态调整并发数逼近真实场景。 - 异常检测:
时序预测模型(如LSTM)监控TPS曲线,自动识别性能拐点(如数据库连接池耗尽)。
10.4 工具链与框架
| 类型 | 工具/框架 | 功能亮点 |
|---|---|---|
| AI测试平台 | Testim, Functionize | 基于AI录制-回放、自愈定位 |
| 视觉测试 | Applitools, SikuliX | 视觉对比、动态元素识别 |
| 缺陷预测 | BugPredict, DeepCode | 代码静态分析 + 缺陷模式匹配 |
| LLM集成 | GitHub Copilot, TestCraft | 自然语言生成自动化脚本(Selenium/Puppeteer) |
| 开源库 | TensorFlow, PyTorch | 自定义模型训练(如图像识别测试模型) |
10.5 实践案例
案例1:电商搜索功能测试
- 问题:手动验证海量商品搜索组合效率低下。
- AI方案:
- 使用遗传算法生成最优搜索关键词组合(覆盖长尾词、特殊字符)。
- NLP模型验证搜索结果相关性(如“iPhone 15”是否排除安卓机型)。
- 效果:测试覆盖率提升60%,发现3个边界条件缺陷。
案例2:金融系统安全测试
- 问题:传统规则引擎难以检测新型业务逻辑漏洞。
- AI方案:
- 基于GAN生成异常交易数据(如超高频小额转账)。
- 强化学习代理模拟攻击者尝试绕过风控规则。
- 效果:发现2个未知漏洞,修复后拦截率提升至99.5%。
10.6 挑战与应对
- 数据质量依赖:
- 问题:模型效果受训练数据(如历史缺陷报告)质量影响。
- 方案:构建数据清洗管道,剔除噪声数据(如重复/无效缺陷)。
- 模型解释性:
- 问题:DL模型决策过程难以追溯(如为何标记某模块为高危)。
- 方案:使用SHAP/LIME等工具可视化特征贡献度。
- 计算资源成本:
- 问题:训练视觉模型需GPU集群支持。
- 方案:采用迁移学习(如Fine-tuning预训练ResNet模型)。
10.7 未来方向
- AI与低代码测试融合:通过拖拽界面 + AI生成复杂逻辑。
- 元宇宙测试:DL验证3D场景渲染一致性(如VR/AR应用)。
- 道德与合规:确保AI生成的测试数据符合隐私法规(如GDPR匿名化)。
1.上传知识库
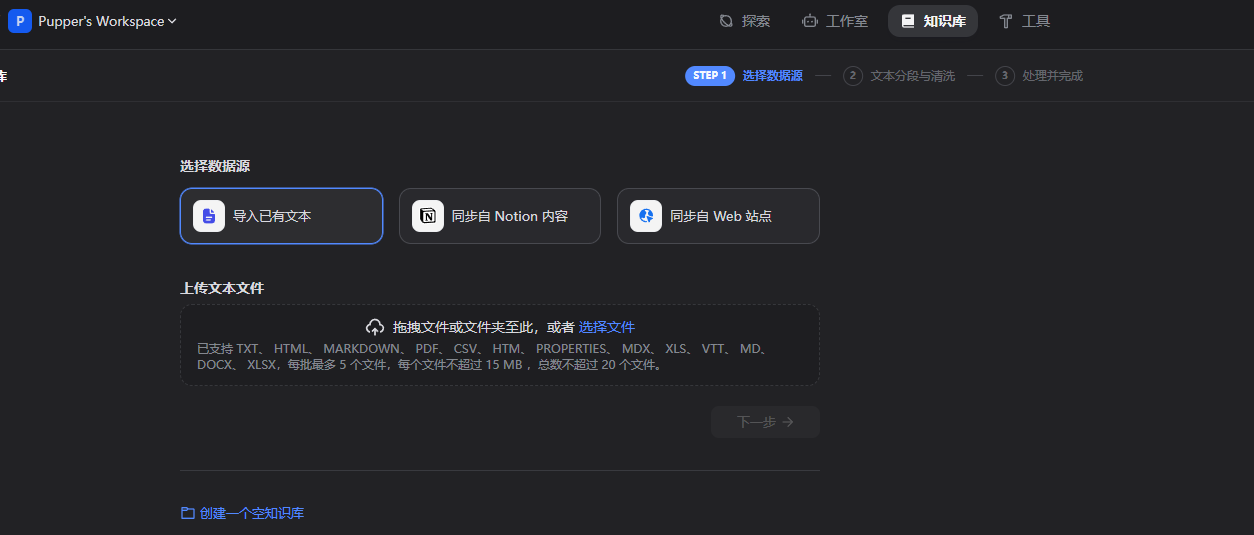
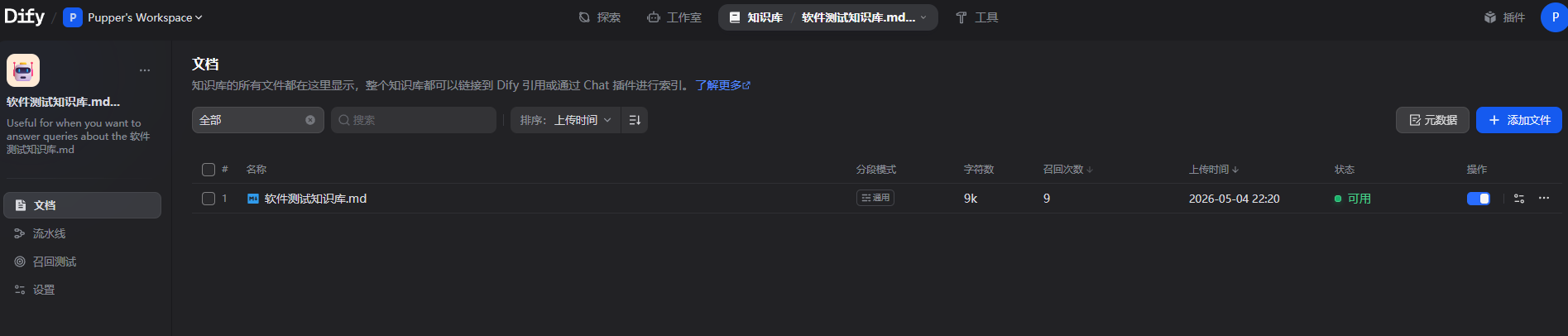
2.创建问答 agent
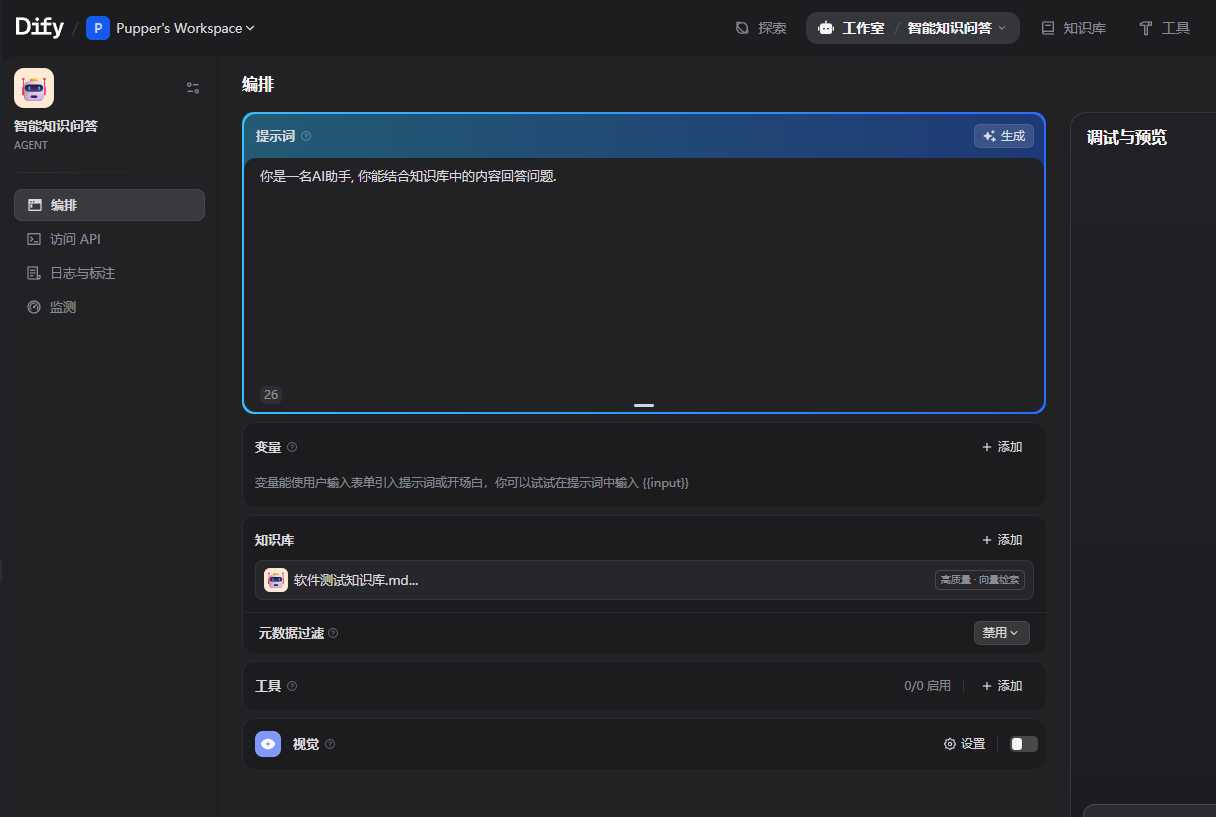
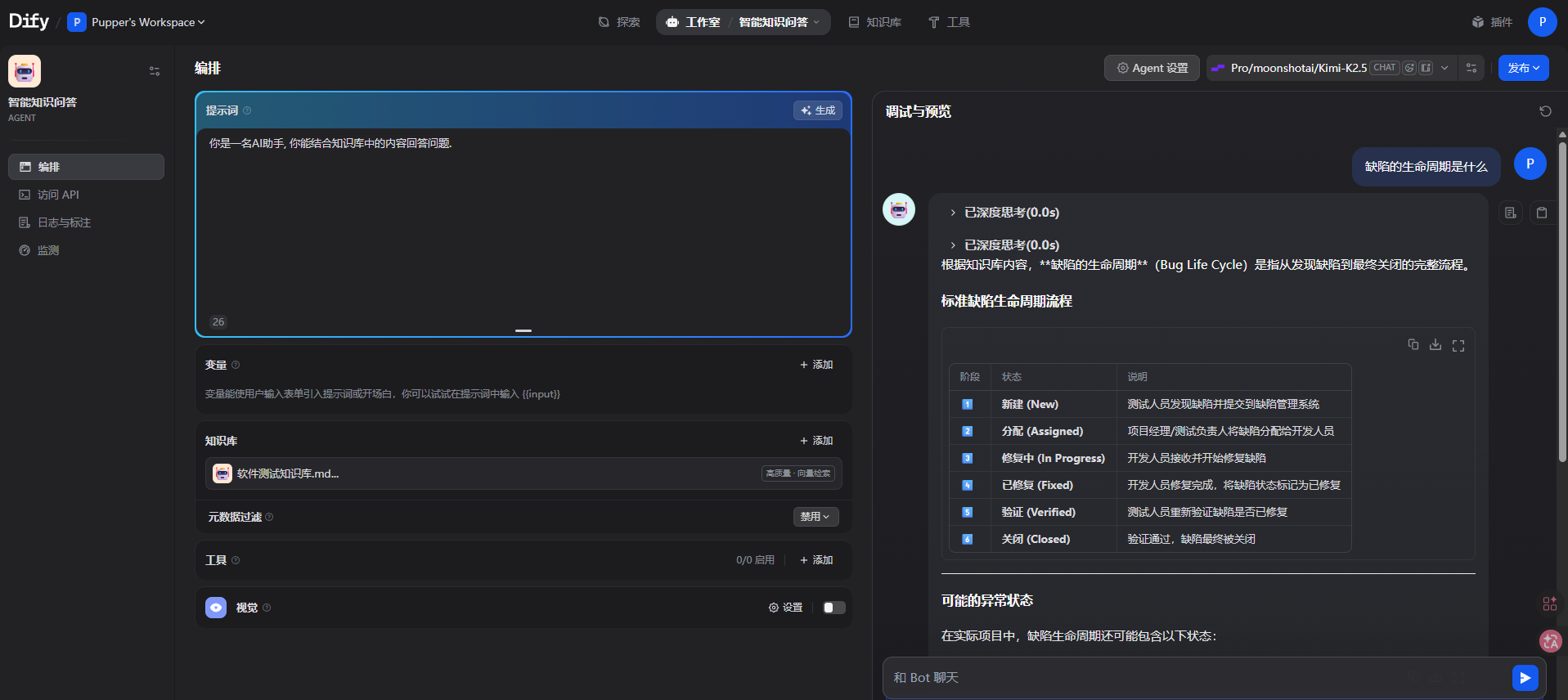




评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果



