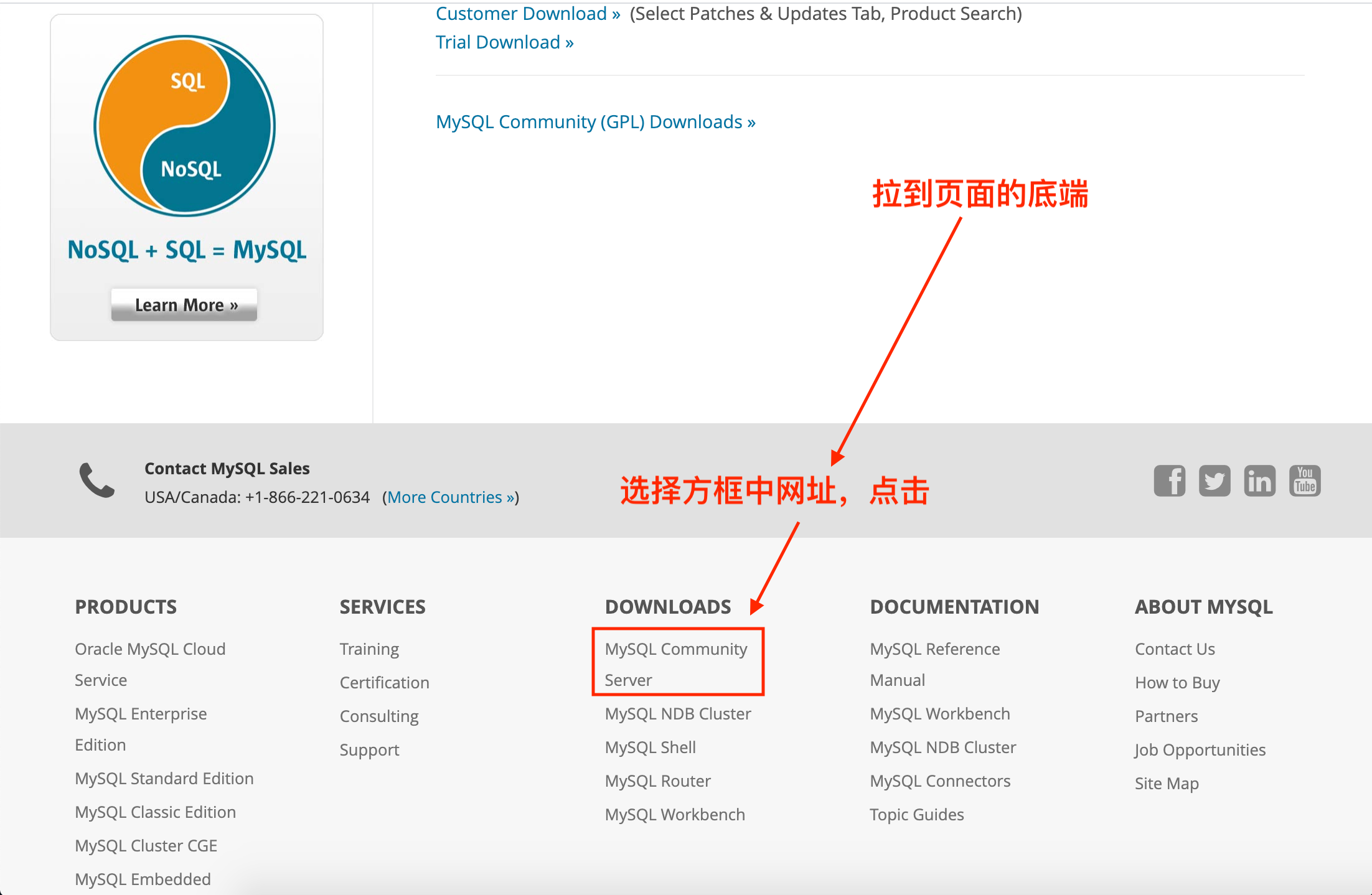
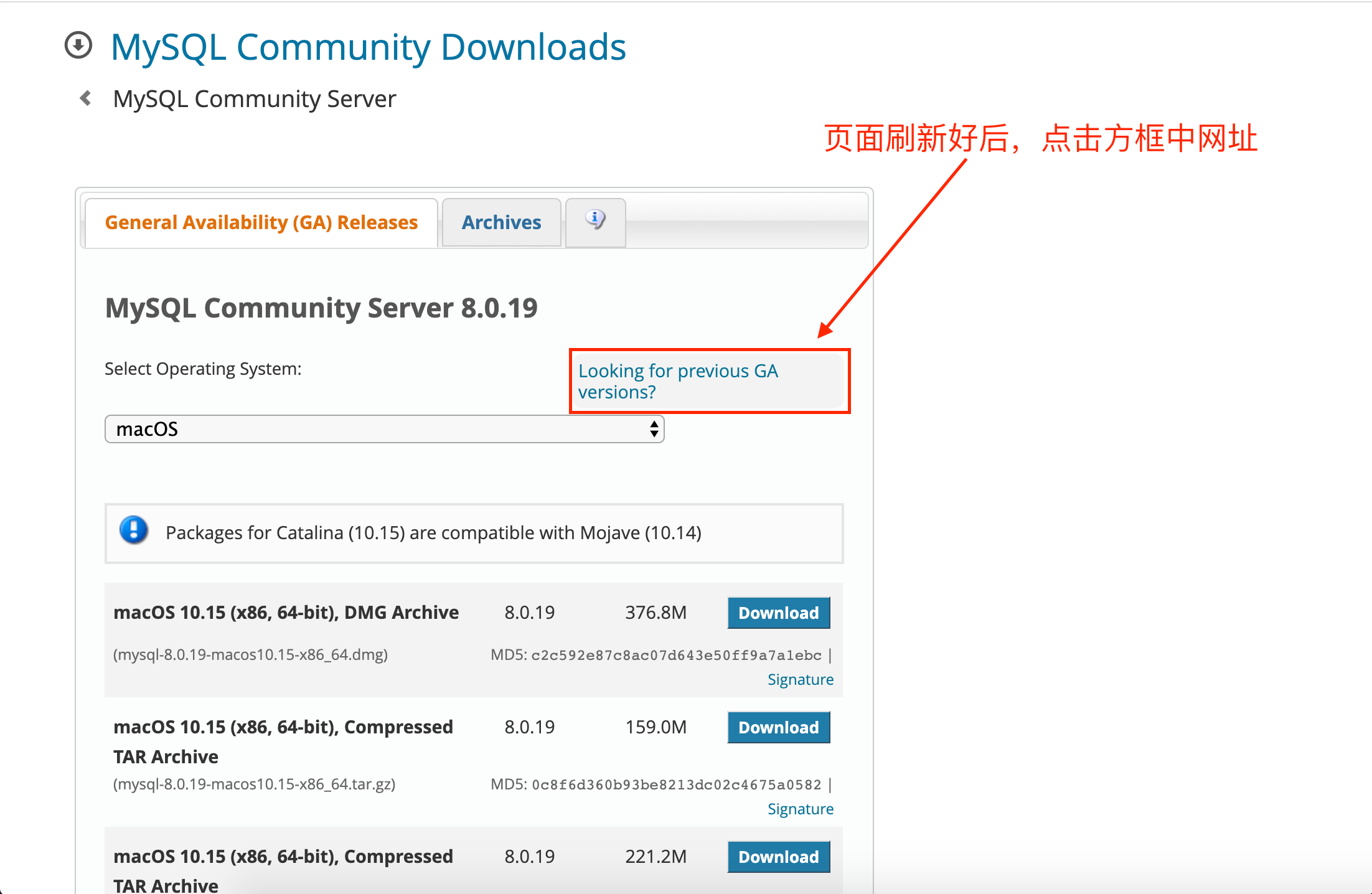
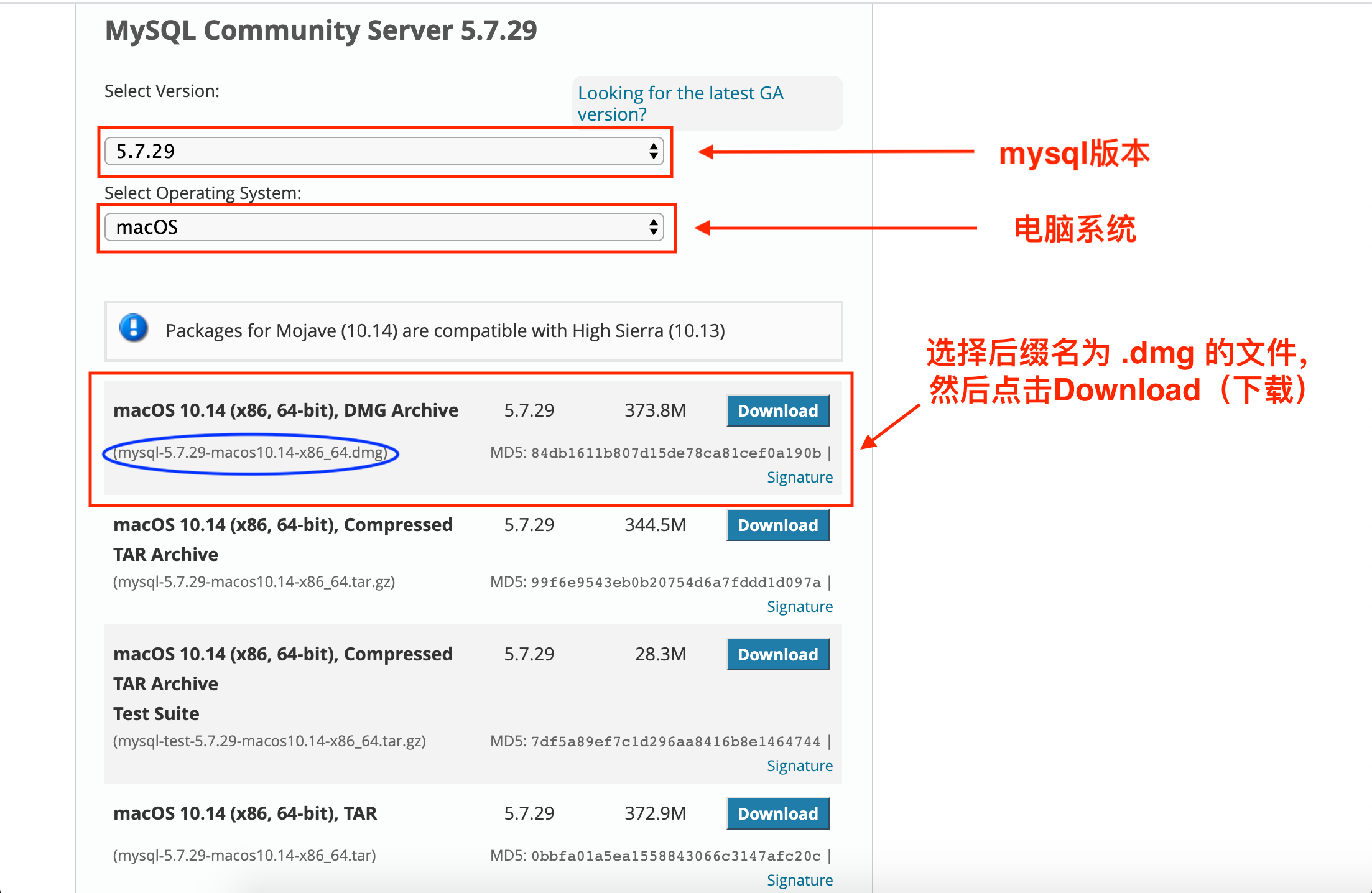
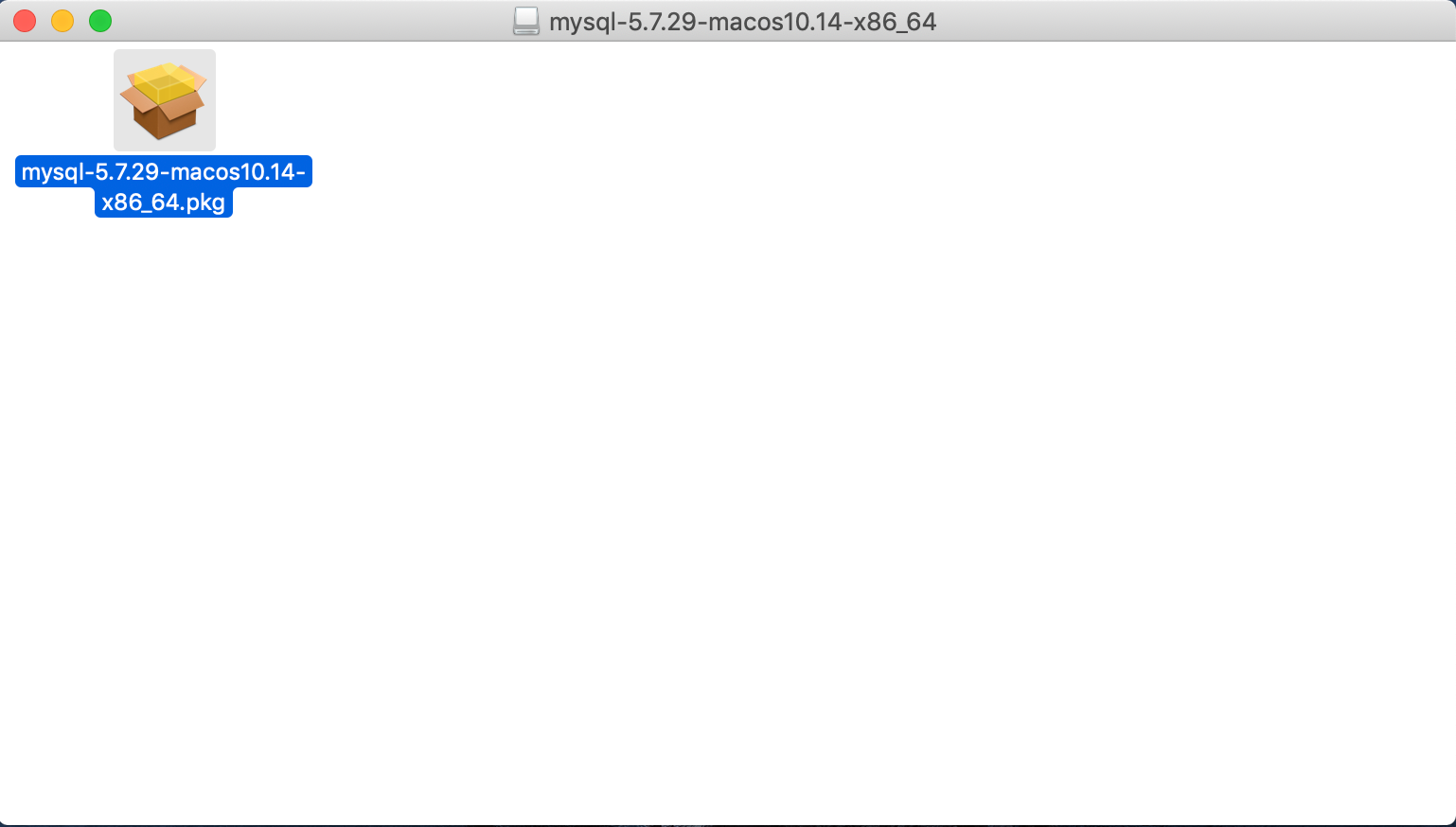
insert into student values(1,'韩信',89,78,90),(2,'张飞',67,98,56),(3,'宋江',87,78,77),(4,'关羽',88,98,90),(5,'赵云',82,84,67),(6,'欧阳锋',55,85,45),(7,'黄蓉',75,65,30);
-- 对结果去重 selectdistinct english from student;
-- 对所有成绩求和 select `name`,(chinese + english + math) as sum from student;
create table mes(id int, content varchar(30), send_time datetime); insert into mes values(1,'北京新闻', current_timestamp()),(2,'上海新闻',now()),(3,'广州新闻',now());
-- current_date() 当前日期 selectcurrent_date() from dual;
-- current_time() 当前时间 selectcurrent_time() from dual;
-- current_timestamp() 当前时间戳 selectcurrent_timestamp() from dual;
-- date(datetime) 返回 datetime 的日期部分 selectdate(`hiredate`) from emp;
-- 显示发布日期,不显示时间 select id, content, date(`send_time`) from mes;
-- 查询在 10 分钟内发布的新闻 select*from mes where date_add(`send_time`, interval10minute) >= now(); select*from mes where send_time >= date_sub(now(), interval10minute);
-- 计算 2011-11-11 和 1990-1-1 相差的天数 select datediff('2011-11-11','1990-01-01') from dual;
-- 计算活了多少点 select datediff(now(), '1989-11-22') from dual;
-- select case when expr1 then expr2 when expr3 then expr4 else expr5 end; -- 如果 expr1 为 true, 则返回 expr2, 如果 expr3 为 true, 则返回 expr4, 否则返回 expr5 selectcasewhen1=3then'条件 1 成立'when2=3then'条件二成立'else'都不成立'end; -- 都不成立
-- 如果 comm 为null, 则显示 0.0 -- 判断是否为 null, 要使用 is null, 不为空 is not null select ename,if(comm isnull, 0.0, comm) from emp; select ename,ifnull(comm, 0.0) from emp;
-- 如果 emp 表的 job 是 clerk 则显示为 职员, 如果是 manager 则显示为 经理, 如果是 salesman 则显示 销售, 其他正常显示 select ename, casewhen job ='CLERK'then'职员' when job ='MANAGER'then'经理' when job ='SALESMAN'then'销售'else job endas job from emp;
-- 查询 员工的名字,工资,部门名称,并按部门编号降序排列 select ename, sal, dname, dept.deptno from dept, emp where dept.deptno = emp.deptno orderby dept.deptno desc;
-- 查询 部门号为 10 的 员工名字,工资,部门名称 select dept.deptno, dname, ename, sal from dept, emp where dept.deptno = emp.deptno and dept.deptno =10;
-- 查询各个员工的名字, 工资, 及工资级别 select ename, sal, grade from emp, salgrade where losal <= sal and hisal >= sal; select ename, sal, grade from emp, salgrade where sal between losal and hisal;
3.自连接
注意事项:
把同一张表当做两张表来使用;
需要给 表 取别名,
表 别名 : 表取别名时, as 可以忽略不写
字段前必须加 表 的别名, 用于区分, 否则报错;
1 2
-- 显示员工名字和 上级的名字 select worker.ename, boss.ename from emp worker, emp boss where worker.mgr = boss.empno;
-- 查询 工资比 30 号部门所有员工工资高的员工信息 select*from emp where sal >all(selectdistinct sal from emp where deptno =30); select*from emp where sal >all(selectmax(sal) from emp where deptno =30);
-- 查询 工资比 30 号部门其中一个员工工资高的员工信息 select*from emp where sal >any(selectdistinct sal from emp where deptno =30); select*from emp where sal >any(selectmin(sal) from emp where deptno =30);
5.多列子查询
语法: (字段 1, 字段 2…) = (select 字段 1, 字段 2 … from…)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
-- 查询 与 ALLEN 部门和岗位完全相同的所有员工,不含其本人 select*from emp where (deptno, job) = (select deptno, job from emp where ename ='ALLEN') and ename !='ALLEN';
-- 查询 每个部门工资高于部门平均工资的个人资料 select empno, ename, job, mgr from emp, (select deptno, avg(sal) as avg_sal from emp groupby deptno) temps where emp.deptno = temps.deptno and sal > avg_sal;
-- 查询 每个部门工资最高的员工资料 select empno, ename, job, mgr from emp, (select deptno, max(sal) as max_sal from emp groupby deptno) temps where emp.deptno = temps.deptno and sal = max_sal;
-- 查询每个部门的 名称, 编号, 地址 和人员数量 select dept.deptno, dname, loc, com from dept,(select deptno,count(empno) as com from emp groupby deptno) num where dept.deptno = num.deptno;
6. 合并查询
union all : 该操作符用于获得两个查询结果的 并集, 该操作符 不会去重; union : 该操作符可以 去重;
1 2
select ename, sal, job from emp where sal >2500unionall select ename, sal, job from emp where job ='MANAGER';
7. 外连接
外连接:
左外连接 : 以左边的表为基准, 全部显示, 右边的表只显示与之匹配的部分;
语法: select … from 表 1 left join 表 2 on 关联条件
表 1 为主表, 表 2 为辅表
右外连接 : 以右边的表为基准, 全部显示, 左边的表只显示与之匹配的部分;
语法: select … from 表 1 right join 表 2 on 关联条件
表 2 为主表, 表 1 为辅表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
create table stu (id int, `name` varchar(32)); insert into stu values(1,'jack'),(2,'tom'),(3,'kity'),(4,'nono'); select*from stu;
create table exam (id int, grade int); insert into exam values(1, 56),(2,76),(11,8); select*from exam;
-- 左外连接 select `name`, stu.id, grade from stu leftjoin exam on stu.id = exam.id;
-- 右外连接 select `name`, stu.id, grade from stu rightjoin exam on stu.id = exam.id;
-- 列出所有部门及其员工,包括没有员工的部门 select dname,ename, job from dept leftjoin emp on dept.deptno = emp.deptno orderby dname ;
-- 创建测试表 create table test06 (id int, tname varchar(32));
-- 查看 表索引 show indexes from test06; show index from test06; show keys from test06; ________________________________________________________________________________
-- 创建视图表, 可以显示 员工编号,名称,部门名称,薪水等级等 (三表联合查询) createview emp_view02 as select empno, ename, dname, grade from dept, emp,salgrade where emp.deptno = dept.deptno and (sal between losal and hisal);
-- 4 工资超过 2850 的员工 select ename, sal from emp where sal >2850; -- 工资在 2850 ~ 1500 之间的员工 select ename, sal from emp where sal >2850or sal <1500; -- 编号为 7566 的员工 select ename, deptno from emp where empno =7566; -- 10 和 30 号部门, 工资超 1500 的员工 select ename, sal from emp where sal >1500and deptno in (10, 30); -- 无上级的员工 select ename, job from emp where mgr isnull;
-- 5 在 1991-2-1 和 1991-5-1 之间入职的员工 select ename, job, hiredate from emp where hiredate between'1991-2-1'and'1991-5-1'orderby hiredate; -- 有补助的员工 select ename, sal, comm from emp where comm isnot nullorderby sal;
-- 6 部门 30 的员工 select*from emp where deptno =30; -- 所有 工作为 CLERK 的员工 select ename, empno, deptno from emp where job ='CLERK'; -- 佣金高于薪金的员工 select*from emp where comm > sal; -- 佣金高于薪金 60% select*from emp where comm > (sal *0.6); -- 部门 10 的 MANAGER 和 部门 20 的 CLERK select*from emp where (deptno =10and job ='MANAGER') or (deptno =20and job ='CLERK'); -- 部门 10 的 MANAGER 和 部门 20 的 CLERK 和 既不是 MANAGER 也不是 CLERK 且 工资大于 2000 select*from emp where (deptno =10and job ='MANAGER') or (deptno =20and job ='CLERK') or (job notin('MANAGER', 'CLERK') AND sal >=2000); -- 收取佣金的不同工作 selectdistinct job from emp where comm isnot null; -- 不收取佣金或佣金少于 100 select*from emp where comm isnullor comm <100; -- 每月倒数第三天入职的员工 select*from emp where hiredate = (date_sub(last_day(hiredate),interval2day)); select*from emp where hiredate = last_day(hiredate) -2; -- 早去 12 年前入职的员工 select*from emp where date_add(hiredate, interval12year) < now(); -- 首字母小写 select concat(lcase(left(`ename`,1)),substring(`ename`,2)) from emp; -- 名字前 5 个字母 selectleft(ename, 5) from emp; -- 名字不包含 R 的员工名字 select ename from emp where ename notlike'%R%'; -- 员工名字前三个字符 selectsubstring(ename,1,3) from emp; -- 替换名字 a 替换 A select replace(ename, 'A', 'a') from emp; -- 入职满 10 年的员工 select ename, hiredate from emp where date_add(hiredate, interval10year) <= now(); -- 按名字排序 select*from emp orderby ename; -- 按入职年限排序 select*from emp orderby hiredate; -- 先按工作排序,再按工资排序 select*from emp orderby job desc,sal; -- 员工姓名,入职年份,月份, 先按月排序,再按年排序 select ename, year(hiredate), month(hiredate) from emp orderbymonth(hiredate),year(hiredate); -- 日薪 selectfloor(sal/30) as'日薪'from emp; -- 2 月入职 select*from emp wheremonth(hiredate) =2; -- 入职天数 select datediff(now(), hiredate) as'入职天数'from emp; -- 员工名字包含 A select ename from emp where ename like'%A%'; -- 日期方式显示入职时间 select from_days(datediff(now(), hiredate)) as'服务天数'from emp;
-- 7 至少有一个员工的部门 select dname from dept where deptno in (select deptno from emp groupby deptno); -- 薪资比 SMITH 多的员工 select*from emp where sal > (select sal from emp where ename ='SMITH'); -- 雇佣时间比上级晚的员工 select emp.ename, emp.hiredate from emp, emp tmps where emp.mgr = tmps.empno and emp.hiredate > tmps.hiredate; -- 部门名称和员工信息,包括没有员工的部门 select dname, emp.deptno, ename, hiredate from dept leftjoin emp on dept.deptno = emp.deptno orderby dname; -- 所有 工作为 CLERK 的员工姓名和 部门名称 select ename, dname, job from dept, emp where dept.deptno = emp.deptno and job ='CLERK'orderby dname; -- 最低薪资大于 1500 的工作 select job, min(sal) min_sal from emp groupby job having min_sal >1500; -- 在部门 sales 工作的员工 select*from emp where deptno = (select deptno from dept where dname ='sales'); -- 薪水高于平均工资的员工 select*from emp where sal > (selectavg(sal) from emp); -- 与 SCOTT 工作相同的员工 select*from emp where job = (select job from emp where ename ='SCOTT') and ename <>'SCOTT'; -- 薪水高于 30 号部门所有员工 select*from emp where sal > (selectmax(sal) from emp where deptno =30) and deptno !=30; -- 每个部门的员工人数, 平均工资, 平均服务年限 selectcount(empno) as'人数', avg(sal), format(avg(datediff(now(), hiredate)/365),2) from emp groupby deptno; -- 所有员工的姓名,部门,工资 select ename, dname, sal from dept, emp where dept.deptno = emp.deptno; -- 所有部门的详细信息及部门人数 select dname, count(dname) from dept, emp where dept.deptno = emp.deptno groupby dname; -- 各个工种的最低工资 select job, min(sal) from emp groupby job; -- MANAGER 的最低薪水 selectmin(sal) from emp where job ='MANAGER'; -- 计算年薪,升序排列 select ename, (sal + ifnull(comm, 0))*12as year_sal from emp orderby year_sal;